
[2021-1 데이터베이스시스템] 1강 데이터베이스의 이해
데이터베이스 시스템의 개요
-
데이터베이스는 간단히 말해 대량의 데이터를 저장 및 관리하고 필요한 데이터를 신속히 검색할 수 있도록 보조하는 장치라고 할 수 있다.
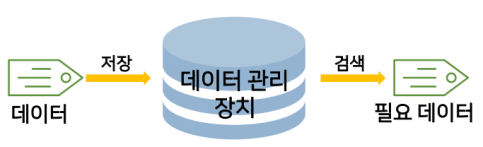
- 데이터베이스 관리 시스템(DBMS: Database Management System)은 한 조직의 연관된 데이터 집합을 다수의 사용자가 공용으로 사용하기 위해 통합 저장하는 소프트웨어 패키지이다.
- DBMS와 함께 사용자에게 서비스 형태로 제공되는 애플리케이션이 포함된 일체의 시스템을 데이터베이스 시스템(Database System)이라고 한다.
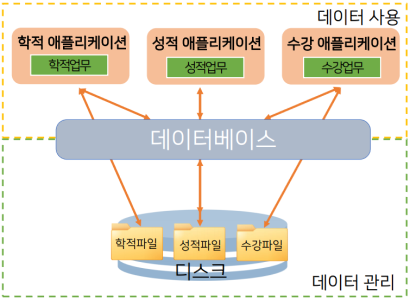
파일 처리 시스템 : 전통적 데이터 관리 방식
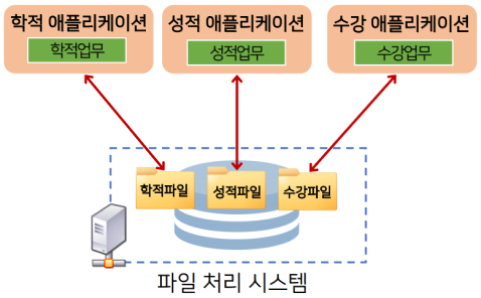
- 파일 처리 시스템은 운영체제에 의해 지원되며, 파일을 사용하여 특정 업무에 해당하는 데이터를 관리하는 방식이다.
-
업무별 애플리케이션이 개별 데이터를 데이터 파일에 저장 및 관리.
-
- DBMS가 사용되기 이전, 대다수의 시스템은 파일 처리 시스템(File Processing System) 방식을 기반으로 운용되었다.
-
하지만, 파일 처리 시스템은 데이터 관리에 여러 문제점을 가지고 있다.
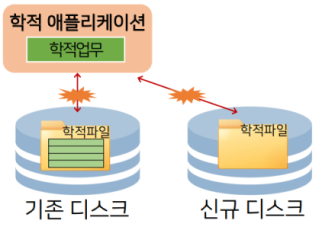
- 데이터 종속(Data Dependency)의 문제
- 저장된 데이터가 특정 하드웨어에서 또는 특정 사용자 및 소프트웨어에서만 사용될 수 있도록 제한되는 문제.
- 물리적 데이터 종속과 논리적 데이터 종속으로 구분할 수 있다.
- DBMS는 데이터를 프로그램과 완전히 독립시킴으로써, 종속으로 인한 문제를 근본적으로 배제시킨다.
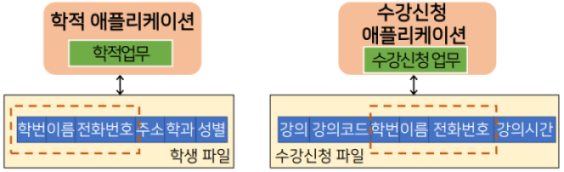
- 데이터 중복(Data Redundancy)의 문제
- 하나의 사항에 대한 데이터가 여러 파일에 중복적으로 저장될 수 있다.
-
동일한 사항에 대한 중복 데이터는 일관성, 보안성, 경제성 측면에서 문제를 발생시킨다.
- 일관성(consistency): 하나의 사실을 나타내는 여러 개의 데이터가 논리적으로 같은 값을 유지하는 것.
- 보안성(security): 논리적으로 동등한 내용의 데이터에 대해 똑같은 수준의 보안을 유지하는 것.
- 경제성(economy): 최소한의 저장공간과 낮은 시스템 갱신 비용.
- 데이터 무결성(Data Integrity) 훼손의 문제
- 데이터의 정확성이 보장되지 않는다.
- 하나의 사실을 표시하는 두 개 이상의 중복된 데이터가 서로 일치하지 않는 경우 발생.
- 저장된 데이터 값이 일정한 형식의 조건(제약조건)들을 만족하지 않는 부정확한 데이터 저장으로 발생.
- 동시 접근의 문제
- 동일 데이터에 다수 사용자의 접근 허용 시 일관성이 훼손.
- 데이터 종속(Data Dependency)의 문제
데이터베이스 관리 시스템의 특징
- 프로그램과 데이터의 독립성 및 추상화
- 프로그램-데이터 독립성(Program-Data Independency): DBMS에서는 데이터 파일의 구조가 프로그램으로부터 분리되어, 데이터의 사용과 데이터의 관리가 분리된다.
- DBMS는 데이터를 공용으로 사용할 수 있도록 프로그램과 데이터를 중재하는 에이전트.
-
데이터 추상화(Data Abstraction): 사용자에게 데이터에 대한 물리적인 정보보다는 개념적인 표현을 제공하여 좀 더 쉽게 데이터베이스를 사용할 수 있게 한다.
- 자기 기술성(Self-Describing)
- 데이터 자체와 데이터에 대한 및 설명(메타데이터)을 관리.
- 메타데이터는 시스템 카탈로그(System Catalog) 또는 데이터 사전(Data Dictionary)에 저장된다.
- 시스템 카탈로그는 데이터 타입이나 포맷과 같은 물리적 정보와 데이터의 의미, 설명 등의 논리적 정보를 관리힌다.
- 다중 뷰
- 각 사용자가 관심을 갖는 데이터베이스 일부만을 표현할 수 있는 기능 제공.
- 이를 통해 각 사용자는 마치 독자적으로 데이터베이스를 접근/사용 하는 것과 같이 보인다.
- 다수 사용자 요청 처리
- 동일한 데이터를 대상으로 다수의 요청을 처리.
- 트랜잭션(Transaction)과 동시성 제어(Concurrency Control) 기능을 통해 다수의 사용자가 동일한 데이터를 동시에 변경하는 경우에도 데이터의 일관성을 보장할 수 있다.
데이터베이스 관리 시스템의 구조
- 데이터 추상화(Data Abstraction)
- DBMS는 내부의 복잡성을 감추도록 설계되었다.
-
따라서, 데이터 추상화와 데이터 독립성을 확보하기 위한 3단계 구조로 구성된다.
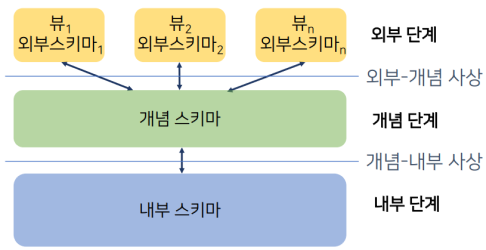
- 내부 단계(internal level)
- 가장 낮은 추상화 단계.
- 원시 수준(raw level)의 데이터 구조, 저장된 레코드의 물리적 순서 등 구체적의 사항을 정의.
- 개념 단계(conceptual level)
- 데이터베이스의 전체 구조를 추상화하는 단계.
- 물리적인 상세사항 등은 배제되며, 데이터베이스에 무엇이 저장되어 있는지와 데이터 간의 관계만 기술.
- 외부 단계(external level)
- 추상화의 최상위 단계.
- 사용자가 관심을 갖는 데이터베이스 일부만 기술하고, 다른 부분은 은폐.
- 내부 단계(internal level)
- 단계 간 사상
- 외부-개념 사상(external-conceptual mapping)
- 개념 스키마에 변화가 생기더라도 외부 스키마에 아무런 영향도 미치지 않는다.
- 논리적 데이터 독립성이 확보된다.
- 개념-내부 사상(conceptual-internal mapping)
- 물리적 변화가 발생해도 개념 스키마에 아무런 영향도 미치지 않는다.
- 물리적 데이터 독립성이 확보된다.
- 외부-개념 사상(external-conceptual mapping)
데이터베이스 언어
-
DBMS는 사용자가 데이터베이스를 쉽게 사용하고 다룰 수 있도록 언어 형태의 인터페이스를 제공.
- 데이터 정의 언어(DDL: Data Definition Language)
- 스키마를 정의.
- 데이터베이스 객체를 생성, 수정, 삭제하기 위한 언어.
- 데이터 조작 언어(DML: Data Manipulation Language)
- 데이터 갱신과 질의를 표현.
- 구조화된 데이터에 사용자가 접근 및 조작(검색, 삽입, 삭제, 수정)할 수 있도록 지원하는 언어.
데이터베이스 시스템 아키텍처
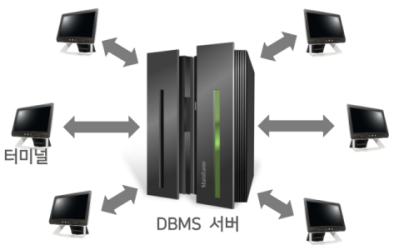
- 중앙집중 방식
- 단일 서버가 다수의 클라이언트 장치를 대신하여 작동.
-
중앙 컴퓨터의 과부하로 전체적인 성능 저하.
- 클라이언트-서버 방식(분산 시스템 방식)
-
클라이언트 장치의 성능 향상으로 자체적인 처리 능력 보유.
- 프로그램 부하 분산 및 시스템의 성능 향상.
-
프로그램 유지보수 비용 절감 및 이식성 증가.
-
DBMS 서버와 클라이언트 컴퓨터 간의 기능에 따라 2계층과 3계층 두 가지 유형이 사용된다.
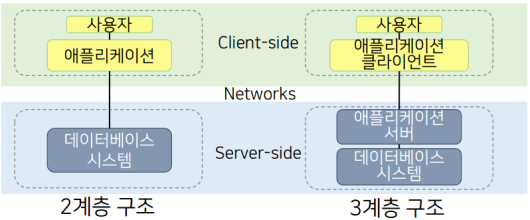
- 2계층 클라이언트-서버 구조(2-tier architecture)
- 소프트웨어 구성요소들이 클라이언트와 서버에 분산
- 기존 중앙집중식에서 클라이언트 쪽으로 사용자 인터페이스와 프로그램이 이동.
- 질의 처리와 트랜잭션 기능은 서버 측에 남아 있다.
- 3계층 클라이언트-서버 구조(3-tier architecture)
- 클라이언트와 데이터베이스 서버 사이에 중간 단계인 애플리케이션 서버를 추가.
- 애플리케이션 서버는 데이터베이스 서버에 접근하는 데 사용되는 비즈니스 규칙(프로시저 또는 제약조건)들을 저장하는 중간 역할 수행.
- 클라이언트 요청 처리 및 데이터베이스 서버에서 처리된 데이터를 클라이언트에게 전달.
- 클라이언트와 데이터베이스 서버 사이에 중간 단계인 애플리케이션 서버를 추가.
- 2계층 클라이언트-서버 구조(2-tier architecture)
-